Matching¶
Matching is done by comparing a set rules and matching it with a parse tree. You can see parse trees for sentences from examples/parser_input.py.
The set of rules is recursive and can match multiple parts of the parse tree.
Rules can be broken down into smaller parts: - Tag - Token - Token Tree - Rules
Tag¶
A tag is a POS (part of speech) tag to match. A list of POS tags used by the Stanford Parser can be found here.
Format:
tag = string
Example:
'NP'
'VP'
'PP'
Token¶
A token is a string comprising of a tag with modifiers/options.
Format:
token = tag:match_label-opts
Example:
'NP:subject-o'
'VP'
'NP:np'
Token Tree¶
A token tree is a recursive tree of tokens. The tree matches the structure of a parse tree.
Format:
token_tree = ( token token_tree token_tree ... )
Examples:
'( NP ( DT ) ( NP:subject-o ) )'
'( NP )'
'( PP ( TO=to ) ( NP:object-o ) )'
Rules¶
Rules are a dictionary of token trees to dictionaries of matching labels to a nested set of rules.
Format:
rules = {token_tree: {match_label: rules}}
Example:
{
'( S ( NP:np ) ( VP ( VBD:action-o ) ( PP:pp ) ) )': {
'np': {
'( NP:subject-o )': {}
},
'pp': {
'( PP ( TO=to ) ( NP:to_object-o ) )': {},
'( PP ( IN=from ) ( NP:from_object-o ) )': {},
}
},
}
When matching a rule to a parse tree, the token tree is first matched. Then, all matching tags are matched to nested rules corresponding to their matching label.
All nested match labels must have a subrule match or the rules will not match.
The first rule to match is returned so the order of match is based on key ordering (use OrderedDict if order matters). Once a rule is matched, it calls the callback function with the context as arguments.
Example¶
Suppose we have the sentence “Sam ran to his house” and we wanted to match the subject (“Sam”), the object to (“his house”) and the action (“ran”).
Sample parse tree for “Sam ran to his house” from the Stanford Parser.
(S
(NP
(NNP Sam)
)
(VP
(VBD ran)
(PP
(TO to)
(NP
(PRP$ his)
(NN house)
)
)
)
)
Simplified image of tree:

tree
Matching:
Parse Tree:
(S (NP (NNP Sam) ) (VP (VBD ran) (PP (TO to) (NP (PRP$ his) (NN house))))
Matched token tree: '( S ( NP:np ) ( VP ( VBD:action-o ) ( PP:pp ) ) )'
Matched context:
np: (NP (NNP Sam))
action-o: 'ran'
pp: (PP (TO to) (NP (PRP$ his) (NN house)))
Rule for ‘( S ( NP:np ) ( VP ( VBD:action-o ) ( PP:pp ) ) )’:
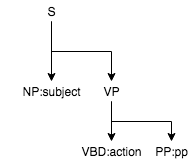
tree
Matching ‘NP’ matches the whole NP tree and converts to a word:
Matched token tree for np: '( NP:subject-o )'
Matched context:
subject-o: 'Sam'
Matching ‘PP’ requires matching the nested rules:
Match token tree for pp: '( PP ( TO=to ) ( NP:to_object-o ) )'
Match context:
object-o: 'his house'
Match token tree for pp: '( PP ( IN=from ) ( NP:from_object-o ) )'
No match found
PP of the sample sentence:

tree
Nested PP rules:
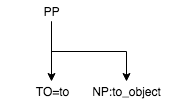

Only the first rule matches for ‘PP’.
Now that we have a match for all nested rules, we can return the context:
Returned context:
action: 'ran'
subject: 'sam'
to_object: 'his house'
Full code:
from lango.parser import StanfordLibParser
from lango.matcher import match_rules
parser = StanfordLibParser()
rules = {
'( S ( NP:np ) ( VP ( VBD:action-o ) ( PP:pp ) ) )': {
'np': {
'( NP:subject-o )': {}
},
'pp': {
'( PP ( TO=to ) ( NP:to_object-o ) )': {},
'( PP ( IN=from ) ( NP:from_object-o ) )': {}
}
}
}
def fun(subject, action, to_object=None, from_object=None):
print "%s,%s,%s,%s" % (subject, action, to_object, from_object)
tree = parser.parse('Sam ran to his house')
match_rules(tree, rules, fun)
# output should be: sam, ran, his house, None
tree = parser.parse('Billy walked from his apartment')
match_rules(tree, rules, fun)
# output should be: billy, walked, None, his apartment